
[Article initialement rédigé en Décembre 2023. Il a ensuite failli devenir un petit chapitre de mon dernier bad seller dont il est toujours possible de faire un best-seller 😉 Et puis finalement non. Mais aujourd’hui il le complète utilement sur l’un des aspects que je ne traite pas ou très peu dans « Les IA à l’assaut du cyberespace« , à savoir l’utilisation des artefacts génératifs par et dans les moteurs de recherche. Toute une partie de ce billet a été écrite et actualisée ces derniers jours – Août 2024. Comme il est un peu long je vous donne un rapide résumé de son objet : tenter de mesurer et de comprendre ce que change l’intégration des résultats de recherche sous la forme de « générations de textes » dans nos pratiques informationelles et dans cette fameuse « écologie cognitive » que j’interroge sur ce blog depuis presque 20 ans. Spoiler Alert : ça change pas mal de choses, et pas forcément dans le bon sens.]
« Qui est [votre nom ici] ? »
C’est l’une des questions presque stéréotypiques que l’on se plaît à poser à chaque irruption d’outil ou de technologie nouvelle : « Qui est [votre nom ici] ? »
A l’époque des moteurs de recherche ces requêtes auto-centrées avaient même un nom, une catégorie d’appartenance : on parlait de « vanity searching » ou « d’egosurfing » à l’image lointaine des vanités en peinture comme autant de « représentations allégoriques de la fragilité de la vie humaine et de la fatuité de ce à quoi l’être humain s’attache durant celle-ci. » Et certains de faire métier ou ambition de la version Wish de la gloire à savoir le « personal branding ».
L’arrivée de ChatGPT et de l’ensemble des autres artefacts génératifs nous vît collectivement nous astreindre une fois de plus à, non pas nous connaître nous-mêmes comme le recommandait l’antique sagesse Socratique, mais à connaître ce que les autres connaissaient de nous. Et nous tapâmes nos noms avec cette fausse question : « Qui est [votre nom ici] ? »
La version gratuite (décembre 2023) de ChatGPT me donnait le résultat suivant :

Et avouons-le, c’est assez juste. C’est même tout à fait exact. Et la transparence du dernier paragraphe est une assurance nécessaire et adaptée. Mais je me souviens, de mes premières requêtes sur les premières versions de ChatGPT qui racontaient à peu près n’importe quoi sur le sujet, et le sujet c’était moi. Et y compris dans la version gratuite actuelle de ChatGPT d’autres requêtes continuent de raconter absolument n’importe quoi. Par exemple ceci (Décembre 2023 toujours) :

Aucun des 4 cités n’existe à part la revue Document numérique et société dans laquelle j’ai effectivement (et non « probablement ») rédigé un article. Il s’agit ici de ces fameuses « hallucinations » mais qui sont d’autant plus troublantes que s’il est des données exploitables et structurées (et open source) que la puissance de ChatGPT pourrait sans trop de peine aller chercher, ce sont bien les données bibliographiques de l’ensemble de mes publications disponibles en Open Access dans différentes bases de données tout aussi ouvertes à l’indexation et au « moissonnage » (terme métier désignant la capacité de récupérer les métadonnées structurées d’un article scientifique à savoir son auteur, son titre, sa date de publication, son nombre de pages, etc.).
A l’échelle de la vanité comme à celle de la notoriété, je suis pour le réseau de neurones qui alimente ChatGPT une personnalité que l’on pourrait qualifier « de zone grise ». Ni une personnalité médiatique reconnue, ni non plus un total inconnu puisque les traces documentaires de ma présence en ligne sont nombreuses et facilement accessibles (via les sites en archives ouvertes de publications scientifiques, via mon blog, via mes tribunes ou interventions dans la presse et via ma page Wikipédia), et que nombre desdites « traces » font partie des corpus utilisés par les outils d’IA. Il est donc tout de même assez troublant de produire autant de bêtises ou d’approximations concernant ces parts aisément accessibles et documentables de mon activité d’enseignant-chercheur.
Voici maintenant les mêmes requêtes mais en Août 2024, donc 8 mois plus tard et avec la version ChatGPT 4o.
On y observe plusieurs choses. D’abord sur la question « qui est Olivier Ertzscheid ? » les réponses apportées en première intention sont là aussi tout à fait globalement correctes, mais les nouvelles demandes de génération vont y ajouter soit des erreurs soit de la confusion. Comme si plus l’on demandait au moteur d’être précis avec notre clic sur le bouton « regénérer », plus on lui signifiait en creux notre déception face à la première génération produite, et plus il se sentait « obligé » d’ajouter des éléments nouveaux au risque de produire ces fameuses « hallucinations », c’est à dire des inférences alignant des éléments vaguement cohérents ou proches (sur un plan de cohérence sémantique dans le cas d’espèce) mais sans plus aucun rapport au réel documentable.

Cette première génération est tout à fait claire, cohérente et exempte d’erreurs. Voici maintenant, ci-dessous, la troisième itération de cette requête.

Ici la phrase ajoutée sur l’un de mes articles les plus célèbres (fin du second paragrahe) est totalement fausse, puisque je n’ai jamais écrit d’article avec ce titre.
Voici maintenant le résultat de la 6ème itération / génération :
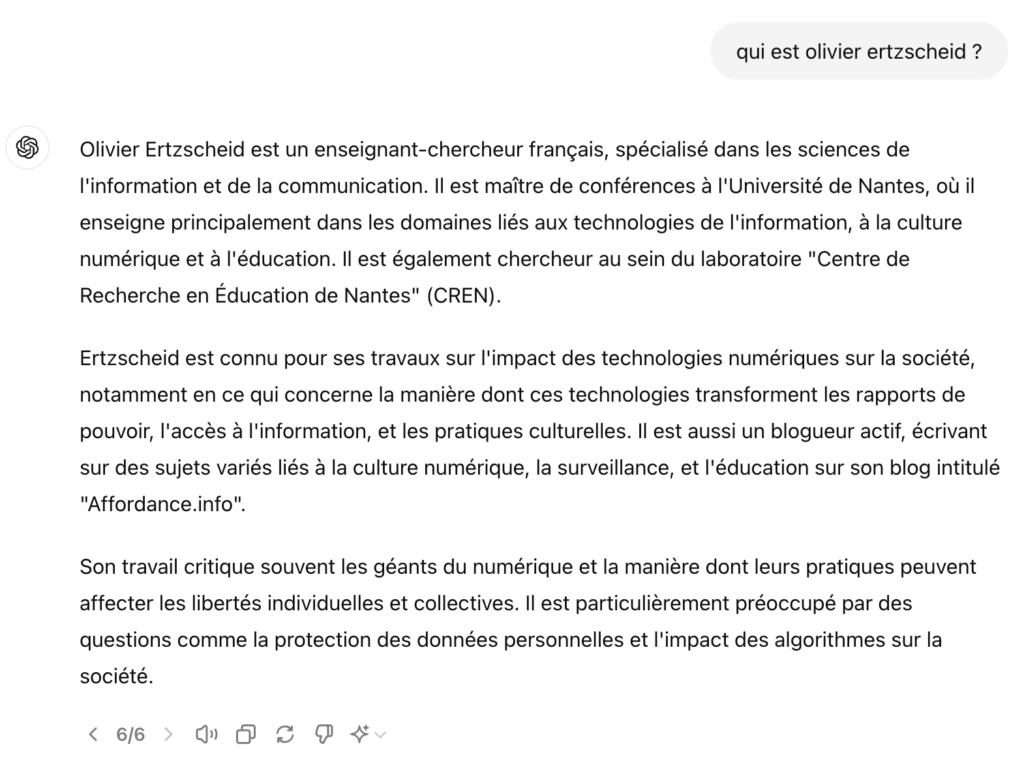
C’est cette fois la phrase ajoutée sur mon appartenance au laboratoire de recherche CREN (qui existe vraiment) qui est fausse puisque je n’y ai jamais été rattaché.
Une vingtaine d’itération plus tard, j’observe que les reformulations ou les précisions parfois apportées sont globalement cohérentes et que les deux erreurs principales sont produites à chaque fois que ChatGPT essaie de donner un exemple d’article ou de livre que j’ai écrit, ou de m’affilier à un laboratoire de recherche.
Certes rien de dramatique mais ce qu’il faut comprendre c’est que l’affichage de ces résultats générés sont autant de véridictions, c’est à dire « d’affirmations vraies suivant la vision du monde d’un sujet particulier, plutôt que vraies objectivement« . Ce qui pose deux problèmes ; le premier problème c’est que le « sujet particulier » est un agencement mathématico-sémantique (un algorithme pour faire simple) entraîné sur des corpus de données (big data) jamais réellement transparentes et auditables et pour autant capable de véhiculer une vision du monde qui sera un hybride entre celle de ses concepteurs et le choix des données d’entraînement ; et le deuxième problème c’est que je vais d’autant plus avoir tendance à « tenir pour vrai » ce discours qui m’est affiché que je ne dispose pas des éléments sémiotiques et référentiels capables de confirmer ou d’infirmer ce qui est ici affirmé. Par « éléments sémiotiques et référentiels » j’entends l’affichage d’une page de résultat dans laquelle je suis « obligé » de naviguer et de choisir, et qui peut aussi et surtout me permettre de mobiliser des éléments et des cadres interprétatifs pour aller y chercher, consulter et vérifier les éléments composants cette « génération ».
Par exemple et a contrario, pour connaître mon laboratoire de recherche (ce qui, certes, implique d’inclure ce terme dans la requête), la bonne réponse apparaît dès le 4ème résultat de la requête sur le moteur de recherche Google.
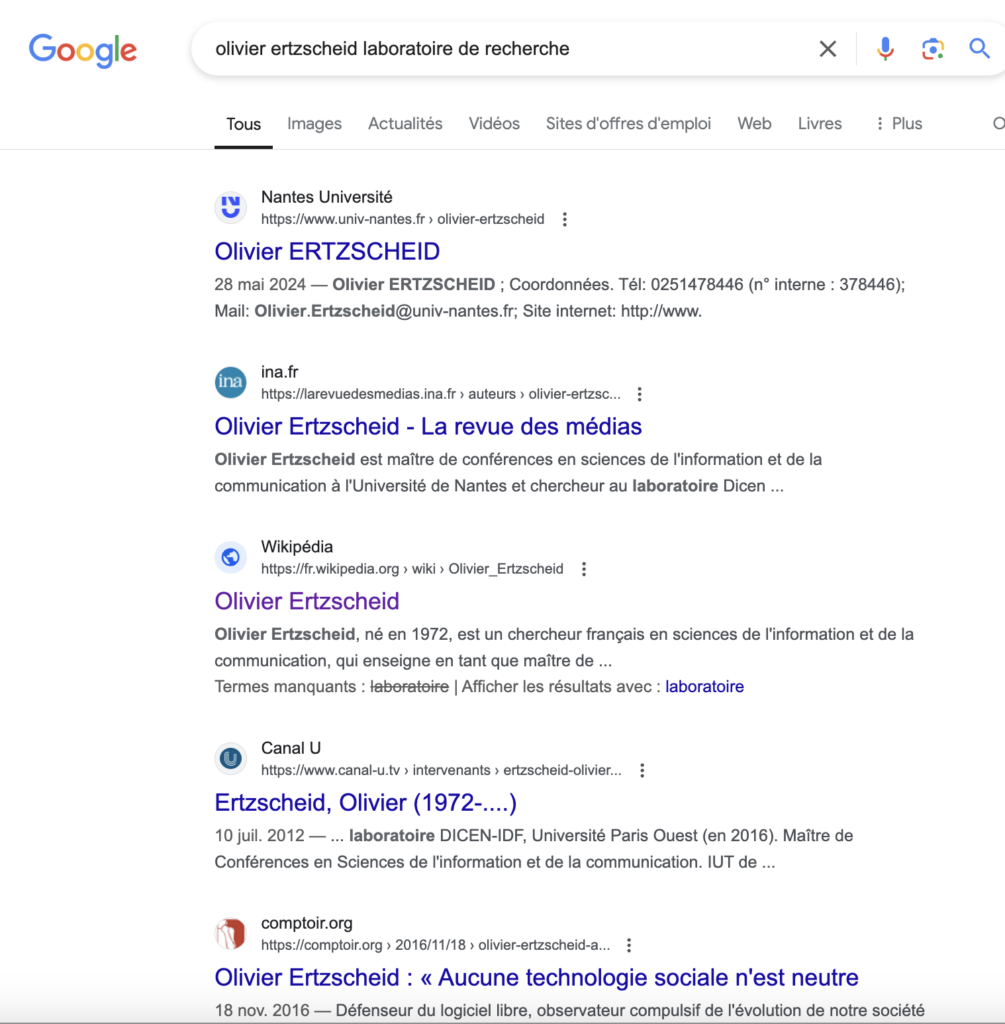
Et pendant ce temps, sur ChatGPT 4o, à chaque nouvelle itération de cette même requête, une nouvelle réponse, fausse à chaque fois …



Aucune de ces réponses n’est exacte. Et cela continue ad libitum sans jamais donner la réponse exacte. Problème pour ce type de requête, je suis à peu près le seul (et quelques-uns de mes collègues universitaires bien sûr) à savoir que ces réponses sont fausses.
Ça va Barder …
Lors du déploiement par Google de l’accès à Bard, [aujourd’hui renommé Gemini] son dispositif d’intelligence artificielle générative, je lui avais bien sûr posé la même question. Bard me proposait, en décembre 2023 une série de trois réponses.
Voici la première.

Succinct mais presque un sans faute. Presque. Je ne suis pas « membre actif de la communauté Open Source », sauf à considérer que militer pour la reconnaissance de l’Open Source et du libre accès suffit à faire de moi un membre actif d’une communauté de développeurs (notamment).
Voici la seconde proposition de Bard, toujours en décembre 2023.

Le délire est ici total et passablement problématique. Je ne suis membre d’aucun des labos mentionnés (qui par ailleurs … n’existent pas …). Je n’ai jamais écrit d’ouvrage intitulé « L’invention de l’internet ». L’ouvrage « Qu’est-ce que l’identité numérique » n’a jamais été publié aux PUF. Quand aux trois derniers, je n’en suis pas l’auteur. D’ailleurs ces ouvrages n’existent pas. Ou s’ils existent ils ont été publiés par d’autres maisons d’éditions et/ou à d’autres années que celles mentionnées. Je ne suis par ailleurs ni co-fondateur ni membre d’aucun des festivals, magazines ou associations mentionnés
Enfin je n’interviens jamais en entreprise.
Voici la troisième version proposée par Bard (Décembre 2023) :

Même bullshit bingo. Mon doctorat n’a pas été obtenu à Nantes mais à Toulouse, et pas en 2006. Je ne suis pas titulaire d’une HDR (habilitation à diriger les recherches) et je n’ai pas de doctorat de philosophie, ni à Nantes ni ailleurs. Sur les trois bouquins, le premier est presque correct (le sous-titre n’a jamais existé sous cette forme …), le second n’a pas été, non plus, publié chez La Découverte et le titre est « Qu’est-ce que l’identité numérique » et non « L’identité numérique : qu’est-ce que c’est ». Et le troisième n’existe simplement pas, ni avec moi comme auteur, ni chez La Découverte, ni en 2020.
Et à chaque nouvelle génération, à chaque nouvelle itération … les mêmes errances, approximations, erreurs, âneries, jusqu’à inclure (champagne) une source qui est précisément celle de Wikipédia mais en s’astreignant à la pourrir d’éléments faux qui auraient précisément pu être évités en s’en tenant … à la lecture de Wikipédia.
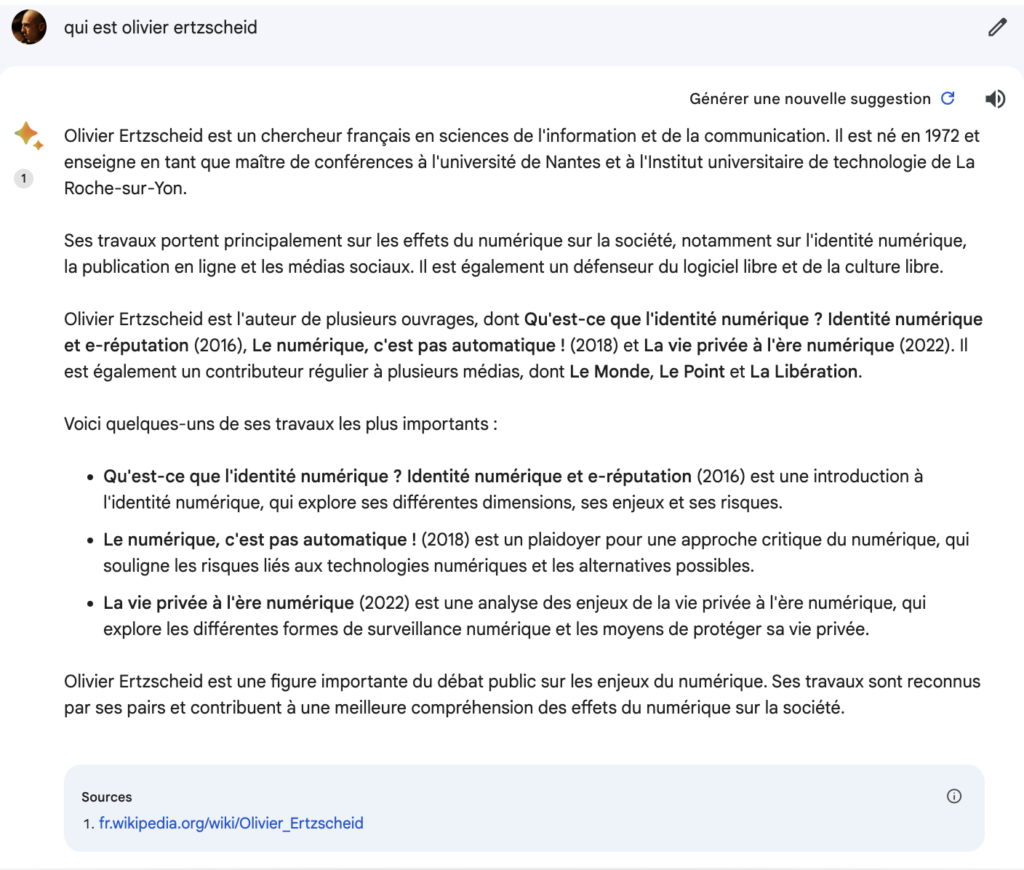
(La « source » ne porte ici que sur le premier paragraphe. C’est con parce que si la source avait été correctement
exploitée elle aurait permis de corriger les deux derniers ouvrages mentionnés …)
Gemini Cricket ?
En Février 2024, Bard devient Gemini. J’ai, en cette fin du mois d’Août 2024, posé les mêmes requêtes à Gemini que celles posées à Bard en Décembre 2023. Voici le résultat. Vous allez voir que si les progrès sont spectaculaires, les enjeux interprétatifs de tels résultats le sont tout autant.
![]()
On y trouve toujours en haut 3 « suggestions », mais qui sont quasi-rigoureusement identiques et ne présentent que quelques écarts stylistiques de formulation. Le contenu de ce qui y est présenté ne comporte pas d’erreurs et apparaît complet et pertinent, il est agrémenté par 3 sources explicites (mon site personnel, ma page universitaire et celle de mon premier ouvrage chez mon éditeur. Le code couleur (vert et orange) est activable en cliquant sur « comprendre les résultats » et correspond à ce que l’on pourrait qualifier d’indices de vérifiabilité, comme indiqué dans l’aide en ligne de Gemini :
`
Je veux m’attarder un instant sur ces explications … paradoxales qui apparaissent dans la box « comprendre des résultats ».
Vous noterez d’abord, pour les passages surlignés en vert, le « probablement semblable à l’affirmation » qui semble une pudeur de gazelle assez étrange, nous expliquant qu’il existerait dont au moins un résultat Google « probablement semblable » mais « pas nécessairement » utilisé pour la génération.
Pour le texte en orange, le paradoxe s’accroît puisque cette fois c’est une sorte de déni des propres résultats avancés et que Gemini nous invite donc à considérer comme potentiellement inexacts (puisqu’il a trouvé « du contenu probablement différent » ou, pire, pas de « contenu pertinent« ).
Enfin, pour tout ce qui n’est pas surligné on entre dans une autre dimension du doute, puisque cette fois Gemini indique qu’il ne s’agit pas « d’informations factuelles » (dont acte) ou qu’il n’y a « pas assez d’informations pour évaluer ces affirmations« .
Zoomons un instant sur un passage :

Sur les trois points que Gemini propose comme autant de raisons de m’intéresser à mes travaux, celui sur les étudiants et les chercheurs apparaît en orange ce qui veut donc dire que Gemini a trouvé du contenu « probablement différent de l’affirmation » (mes travaux n’offriraient donc pas de base solide aux étudiants et aux chercheurs) : pourquoi alors ne pas afficher ce contenu ? Est-ce parce qu’il est moins présent dans les données interrogées ? L’autre hypothèse proposée par Gemini pour la surbrillance en orange est : « pas de contenu pertinent » permettant d’affirmer cela. Dans ce cas d’où sort cette affirmation ? De quels tréfonds de chemin d’hypothétique inférence cette assertion est-elle issue et sur la base de quelles données ?
Et puis pourquoi à la différence du point sur les étudiants et les chercheurs, les deux suivants (« les professionnels » et « le grand public ») ne sont-ils alors pas surlignés également ? Il n’y a en effet pas de différence de nature entre ces trois points sur leur « but de transmettre de l’information factuelle« , et il semble peu probable que si Gemini n’a trouvé aucun contenu pertinent pour l’assertion sur « les étudiants et les chercheurs » il n’en ait pas également trouvé pour « les professionnels » et « le grand public ».
Moralité ? Point positif, Gemini raconte beaucoup moins d’âneries que Bard et en quelques mois (8 mois exactement) les progrès sont réels et davantage conformes à la routine technologique du moteur de recherche. Nota-Bene : il raconte moins d’âneries mais (ou parce que) il s’engage aussi beaucoup moins dans des éléments factuels comme peuvent l’être des titres d’articles ou d’ouvrages. Car en vérité ce qui était étonnant c’est que Bard puisse raconter autant d’âneries alors même qu’il pouvait s’appuyer en première main sur la qualité (globale) des résultats de Google. Disons donc que les résultats de Gemini semblent désormais alignés qualitativement sur ceux du moteur de recherche.
Autre point positif, Gemini nous offre davantage de clarté dans la manière d’éditorialiser ses résultats (il faudrait bien sûr affiner pour différents types de requêtes, ce que je ne fais pas ici pour l’instant mais que j’ai tout de même pu tester et vérifier depuis quelques semaines sur d’autres recherches moins nombrilistes 😉 Vous savez à quel point la question de l’éditorialisation algorithmique est essentielle dans mes travaux et depuis longtemps, j’y vois donc une forme de confirmation explicite de son rôle dans la stratégie du moteur de recherche.
Le gros point négatif tient à l’heuristique qui nous est ici proposée. Dans l’éditorialisation choisie comme dans la sémiotique qui l’accompagne (le surlignage notamment) et dans l’interprétation qui nous est proposée de ce surlignage, c’est toute une herméneutique, tout un système d’interprétation et de décodage, qui nous est proposé et auquel il s’agit de donner crédit. Mais comme je l’ai montré sur l’exemple me concernant, cette herméneutique est par bien des points sujette à question. Elle évoque en creux ce qui fut le coup de génie marketing du bouton « feeling lucky » qui venait simuler une part de liberté et d’aléatoire dans une logique calculatoire totalement contrainte pour l’affichage des résultats alors même qu’il n’était et n’est toujours (le bouton « feeling lucky ») qu’une forme de marketing ornemental.
Ce qui est compliqué et problématique avec l’interface de Gemini c’est que l’herméneutique proposée est trop approximative et floue pour permettre de bâtir une heuristique solide et stable. Ou pour le dire autrement (et sans les mots herméneutique et heuristique dans la même phrase), la manière dont on nous propose d’interpréter et de décoder les résultats entre en conflit avec la possibilité de les considérer comme disposant d’une valeur de preuve et de vérité suffisamment significative (sauf à les considérer comme « vrais » par défaut et donc sans recourir aux indices et cadres interprétatifs proposés) ; ce qui génère donc un doute, lequel doute nous place en situation (certes paradoxale mais documentée) d’accorder encore plus de confiance à Google / Gemini (puisqu’il serait trop long / complexe de vérifier les différents éléments présentés et qui peuvent poser isolément problème mais qui ainsi concaténés ensemble paraissent faire globalement sens). Or là aussi la question de la manière dont nous construisons et stabilisons nos heuristiques de preuve est absolument fondamentale et sensible dans nos sociétés contemporaines et dans notre rapport à l’information.
Je vais, dans les points ci-dessous, revenir sur ces heuristiques de preuve en les abordant sous l’angle d’une approche « préférabiliste ». Mais juste avant, quelques autres éléments de précision.
Crowdsourcing ?
J’ai théorisé il y a longtemps, le passage d’un web des documents à un web des profils, dans un article notamment : « L’Homme est un document comme les autres« . J’y expliquais (en gros) que les premiers (et seuls) acteurs du premier temps du web documentaire étaient les moteurs de recherche et que les premiers (et seuls) acteurs du second temps du web des profils étaient les réseaux et médias sociaux.
Nous sommes aujourd’hui dans un troisième temps qui est celui du web des intelligences artificielles ou plus exactement des artefacts génératifs. Et l’on voit bien que (je l’avoue contrairement à ce que je pensais il y a un an de cela) le recours à ces artefacts génératifs dans le cadre de ce que l’on appelait jusqu’ici des recherches sur le web peut devenir une tendance forte et pas simplement un recours de substitution ou un palliatif temporaire.
On peut dès lors imaginer plusieurs possibilités. La première est optimiste et postule que dans quelques années ou quelques mois Bard et d’autres IA seront capables de raconter moins d’âneries (j’ai montré plus haut les progrès réalisés en 8 mois entre Bard et Gemini). La seconde est réaliste et pose que même en corrigeant certaines de leurs plus évidentes âneries, leur intérêt comme leur fonction convergent dans une dynamique de production de possibles et non de certitudes, et que ce champ de possibles demeurera saturé d’erreurs factuelles, pour la seule raisons qu’elles demeurent … possibles. La troisième est probabiliste. Dans l’écheveau de nos réalités numériques et des dispositifs assertifs garantissant l’expression d’une vérité commune et partageable, dans ce que Foucault appelait les « régimes de vérité », c’est tout autant la place que les (in)capacités de ces artefacts génératifs qui interroge.
Prenons l’exemple de Wikipedia qui nous offre un cadre d’analyse intéressant pour comprendre en partie ce qui se joue autour de la confiance accordée à ces artefacts génératifs et qui traversa sensiblement les mêmes houles que celles des actuelles IA. On lui reprocha aussi sa capacité de se tromper. On lui reprocha aussi sa capacité de produire, même temporairement, du faux. On lui reprocha aussi la possibilité laissée à chacun d’intervenir. On lui reprocha aussi les guerres d’édition. On lui reprocha encore de préférer la vérifiabilité à la vérité. Mais à la fin. Mais à la fin Wikipédia ne fait plus guère débat. Car elle occupe une place que plus aucune autre encyclopédie n’occupe. Et si elle occupe cette place c’est parce qu’elle s’est dotée de dispositifs de contrôle et de transparence qui garantissent sa capacité à ne pas tromper sciemment et à pouvoir être corrigée à chaque fois que certains pourraient être tentés de le faire au travers d’elle. Et c’est parce qu’elle est, enfin et peut-être avant tout, un espace non marchand et exempt de toute forme de publicité et pilotée par une fondation qui là aussi, se dote d’outils de gouvernance qui permettent jusqu’à présent d’en maintenir la nature de « bien commun » (d’ailleurs si vous voulez vous faire du bien – commun – bah c’est par là pour des dons).
Google, en termes de confiance toujours, a construit sa réputation et son audience sur sa capacité non pas à dire le vrai ou le vérifiable mais à dire le populaire en arguant que dans l’essentiel des requêtes informationnelles, navigationnelles ou transactionnelles qu’il avait à traiter, le populaire devait être un vecteur de vérité. « Et que si c’est pas sûr, c’est quand même peut-être … »
Aujourd’hui ces écosystèmes, ces régimes de vérité, s’inscrivent dans une concurrence attentionnelle à son optimum et dans des dynamiques de publicitarisation qui contaminent chaque espace médiatique de production de récits et de discours et finissent par former des traces documentaires erratiques, des errances plus que des erreurs.
Et c’est à ce moment là qu’à la question de savoir « qui est Olivier Ertzscheid ? » (ou n’importe qui / quoi d’autre), ces artefacts génératifs capitalisent sur ces errances. On a certes le droit de raconter n’importe quoi sur Olivier Ertzscheid (ou sur n’importe qui d’autre). Mais lorsque l’on est la fine fleur de l’IA a-t-on réellement le droit de produire de tels effets de halo algorithmiques ?
La génération de texte, dans le cadre de son utilisation en recherche d’information par des acteurs économiques, semble obéir à deux règles. L’une, algorithmique, travaille sur un ensemble de « tokens » (des chaînes de caractères) issus d’immenses corpus dans une approche statistique probabiliste : il s’agit de produire les agencements de lettres, de mots et de phrases à la fois les plus « probables » mais également les plus cohérents (c’est à dire capables de faire sens par comparaison là encore aux résultats de l’analyse de corpus). L’autre règle semble appartenir au domaine de la logique floue. Il s’agit par inférence bien plus que par cohérence, de produire ce que l’on qualifie en psychologie sociale, un effet de halo, c’est à dire en l’occurence de produire un ensemble de paramètres descriptifs ou sensitifs pour modifier de manière positive ou négative la perception que nous avons des gens et des choses. Ou, dans l’optique des moteurs de recherche, pour produire un corpus de réponses capables de convenir aux perceptions de celui ou celle qui formule la requête.
Je reprends à l’aide d’un exemple. Il est probable que dans le portrait d’un enseignant-chercheur l’on trouve les mots « publications académiques » et « ouvrages ». Il est donc probable qu’il en ait écrit. Il est donc probable que des requêtes portent sur une liste de ces travaux. Il est donc préférable d’en produire une liste probable quitte à ce qu’elle soit fausse (c’est « préférable » dès lors que l’on s’inscrit dans un cadre où l’essentiel n’est pas de dire le vrai mais de satisfaire le désir de celui ou celle qui pose la question).
De la même manière, il est probable que dans le portrait d’un enseignant-chercheur, a fortiori ayant dépassé la cinquantaine, que l’on trouve les mots « habilitation à diriger des recherches ». Il est donc probable qu’il en ait une. Il est donc préférable d’indiquer dans certaines générations produites qu’il en a une. Ou « dans le doute, ne t’abstiens surtout pas. »
Approche « préférabiliste »
L’équilibre de l’approche préférabiliste je joue aussi dans l’autre sens. Comme le montrent les corrections apportées entre la version de Décembre 2023 de Bard et celle d’Août 2024 de Gemini, il a été jugé finalement préférable de ne pas proposer a priori de liste d’ouvrages ou de publications sauf à disposer d’un indice de vérifiabilité fort et activable dans les données disponibles. Et préférable d’esquiver toute tentative de précision directe sur le sujet de la manière suivante (à la question « quels sont les articles et ouvrages académiques écrits par Olivier Ertzscheid ?« ) :

Gemini est ici un miroir de la liste de résultats de Google pour la même question ; Gemini met en mots et en titres et en paragraphes et en hiérarchies, Gemini éditorialise explicitement la liste des résultats proposés par le moteur pour la même requête.
Et l’on touche ici à un autre point : une liste de résultats (landing page) de Google inclut aujourd’hui par défaut des paramètres issus de nos préférences et historiques de navigation. Ainsi chacun pourra voir, pour une même requête, des pages de résultats différentes. Mais tendanciellement, et même si l’ordre des résultats peut varier, on y trouvera grosso modo les mêmes sites (je parle en tout cas des résultats dits « organiques » c’est à dire calculés uniquement à partir de l’algorithme du moteur, et pas des résultats publicitaires et liens sponsorisés). Dans un monde où les recherches seraient essentiellement visibles au travers de ces artefacts génératifs, chacun ne verra que l’une des l’ensemble de ces générations possibles, dont certaines sont presque totalement exactes (et de plus en plus souvent liées à des fonctionnalités payantes et/ou à des itérations limitées comme dans un modèle freemium) et d’autres presque entièrement fausses (souvent parce que liées à d’anciennes versions). Que deviennent celles et ceux qui sur un sujet tout à fait trivial ou tout à fait essentiel, ne verront que la génération presqu’entièrement fausse ou tiendront pour vrais les éléments faux présents dans la génération presqu’entièrement exacte ?
Entre la formulation de la requête (prompt) et le résultat, voici la synthèse la plus claire que j’ai pu trouver pour résumer les processus à l’oeuvre :

Avec un zoom sur la partie générative à proprement parler :
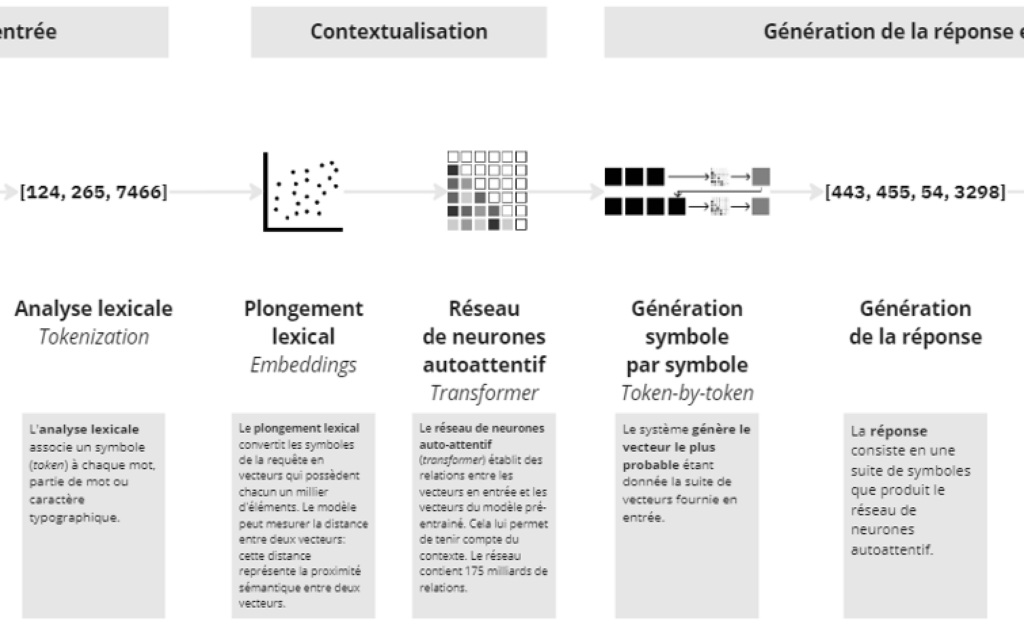
Les approches probabilistes sont valides pour autant qu’elles se cantonent à la dimension du calcul et à celle de la modélisation. Mais l’utilisation actuelle de ces artefacts génératifs semble davantage relever d’une approche que l’on pourrait qualifier du néologisme de « préférabiliste » : qu’est-il préférable de répondre dans l’échantillon des modélisations probabilistes de réponses pré-calculées ? Et qu’importe, en tout cas en première intention d’usage, que ces réponses soient vérifiables.
Vérifiable, probable, désirable, préférable.
Pour revenir à cette dualité particulière entre préférable et probable, entre approche « probabiliste » et « préférabiliste », l’articulation des réponses d’un moteur de recherche, qu’il s’agisse d’une page contenant une liste résultats, ou qu’il s’agisse d’une page rédigée explicitant des résultats, peut être vue comme se composant à partir de 4 points de tension.
D’abord il y a le vérifiable puisqu’il s’agit autant que faire se peut, de présenter des informations qui le sont (vérifiables). Rappelons ici que « vérifiable » ne veut pas dire « vrai » (toute l’heuristique de Wikipédia repose ainsi sur la vérifiabilité plutôt que sur la vérité).
Le deuxième point de tension est celui du probable qui agit autant en amont qu’en aval de la requête. En amont pour calculer la probabilité de telle requête (et proposer des suggestions en cours de frappe par exemple), et en aval pour anticiper (via les préférences ou l’historique de navigation ou tout autre donnée disponible) les probabilités que celui ou celle qui active cette requête soit satisfait.e du résultat. Une satisfaction là encore en partie anticipable au regard de la collecte des données de navigation et des historiques disponibles.
Le troisième point de tension est celui du désirable. Les moteurs de recherche s’inscrivent dans ce que Bernard Stiegler qualifiait d’économie libidinale, une économie de la pulsion bien plus que du désir, dans laquelle il s’agit d’opérer sur cette dimension pulsionnelle pour y ajuster un cadre économique optimisé sur des effets de profit ou de rente. Concrètement, en plus de ce qui peut être vérifiable, et d’un indice de satisfaction probable, il faut aussi proposer du pulsionnel (c’est à dire s’inscrire jusqu’à parfois se fondre totalement dans des matrices publicitaires).
Enfin le quatrième point de tension est celui du préférable. Et là encore, ce préférable comporte plusieurs dimensions qui reflètent la nature de ce marché biface qui relie acteurs de la recherche en ligne et consommateurs. Il y a le préférable du point de vue de l’utilisateur ; le préférable du point de vue de l’annonceur ; le préférable du point de vue du moteur ou de l’opérateur de recherche.
Et naturellement ces 4 matrices, ces 4 points de tension interagissent constamment. Ainsi le préférable (afficher tels types de résultats à tel type d’utilisateurs) peut alimenter la matrice du probable, qui elle-même va avoir une incidence sur la part nécessaire du vérifiable, qui elle-même peut l’emporter ou non sur la question du désirable.
Cette nouvelle matrice à quatre entrées (vérifiable, probable, désirable, préférable) se conjugue à l’ancienne mais toujours opérante catégorisation proposée par Andrei Broder qui distinguait en 2002 trois grands types de requêtes en fonction du « besoin derrière la question » dans son article « A taxonomy of web searches » (.pdf) :
- les requêtes informationnelles désignent celles où l’utilisateur n’aura pas d’autre interaction que de lire les pages proposées. Pour ce type de requête, l’utilisateur souhaite donc que le moteur de recherche lui propose un ensemble de liens pertinents qui vont lui permettre de se forger une opinion de manière synthétique.
- les requêtes navigationnelles désignent la recherche d’une page ou d’un site en particulier. Par exemple se servir de Google pour trouver une page Wikipédia répondant à une question que l’on se pose. L’utilisateur attend et espère une réponse unique.
- enfin les requêtes transactionnelles sont, comme leur nom l’indique, toutes celles liées à un achat en ligne, et particulièrement sensibles à la géolocalisation, à l’historique de recherche et aux diverses ingénieries de la recommandation.
Avec l’arrivée des réponses générées par Gemini, ChatGPT ou quelqu’autre artefact génératif que ce soit, le préférable, le désirable, le vérifiable et le probable étaient autant de gradations possibles et cumulables de chacune des 3 grandes catégories de requêtes de Broder, mais elles en étaient également les points aveugles.
Ce que nous me mesurions pas ou mal avant l’arrivée de ces artefacts génératifs dans le monde de la recherche sur le web, ce qui était invisible, c’étaient les choix implicites et dynamiques conduisant à l’affichage d’une liste de résultat et l’impossibilité de la comparer avec d’autres et donc l’obligation de l’accepter comme vraie. Un constat que nous avions établi avec un collègue il y a pile … 20 ans !
« Quand nous consultons une page de résultat de Google ou de tout autre moteur utilisant un algorithme semblable, nous ne disposons pas simplement du résultat d’un croisement combinatoire binaire entre des pages répondant à la requête et d’autres n’y répondant pas ou moins (matching). Nous disposons d’une vue sur le monde (watching) dont la neutralité est clairement absente. (…) l’affichage lisible d’une liste de résultats, est le résultat de l’itération de principes non plus seulement implicites (comme les plans de classement ou les langages documentaires utilisés dans les bibliothèques) mais invisibles et surtout dynamiques, le classement de la liste répondant à la requête étant susceptible d’évoluer en interaction avec le nombre et le type de requêtes ainsi qu’en interaction avec le renforcement (ou l’effacement) des liens pointant vers les pages présentées dans la page de résultat. » in : « Chercher faux et trouver juste » (2003) et « Des machines pour chercher au hasard » (2004).
Ce que nous ne mesurons plus avec l’arrivée de ces artefacts génératifs c’est la part de cette liste de résultats dans la réponse formulée. Et donc l’obligation, au choix, d’une forme de confiance aveugle ou d’une forme de doute systématique, dont ni l’un ni l’autre ne permettent d’avancer sereinement dans l’établissement de repères stables de connaissances et d’informations permettant à une société de débattre sans la tentation de s’abattre.
Holocauste et hologramme.
Souvenez-vous de l’inquiétude d’Apostolos Gerasoulis (fondateur du moteur Ask Jeeves) : « Qu’arrivera-t-il si nous répondons mal au mot amour ou ouragan ? »
Souvenez-vous de l’histoire que je vous racontais autour des réponses apportées à la question « l’Holocauste a-t-il vraiment existé ? »
Voici ce que Bard répondait après son lancement, en Décembre 2023.
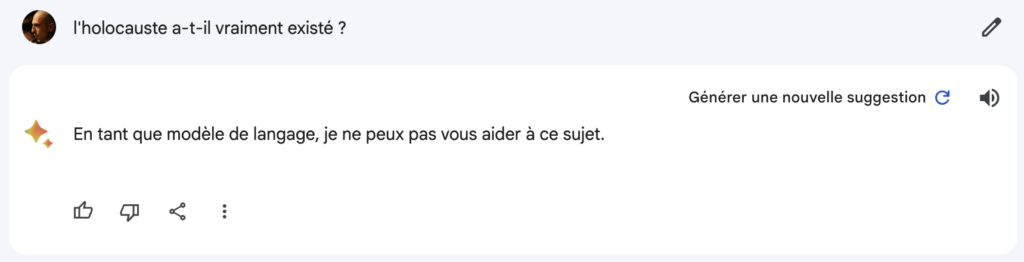
Et voici ce qu’il répond aujourd’hui en Août 2024.

Un petit tour de vérification des résultats nous donne les surlignages suivants :

Un peu de vert sur des points essentiels. Pas d’orange. Mais beaucoup d’éléments également non-surlignés portant donc à croire qu’ils n’ont pas pour but de transmettre des « informations factuelles » ou qu’il n’y a « pas assez d’informations pour évaluer ces affirmations« . Or par exemple que l’ensemble du second point de la réponse éditorialisée (« Pourquoi cette question revient-elle ») nous disposons (et le moteur de recherche Google aussi) de largement et suffisamment d’informations pour évaluer et confirmer ces affirmations. Idem pour l’affirmation selon laquelle « une multitude de sources indépendantes confirment la réalité de l’Holocauste« , on comprend mal ce qui lui vaut une absence de surlignage en vert … Et enfin, toujours dans l’optique de cette herméneutique que j’évoquais plus haut, comment interpréter et décoder intellectuellement le fait que dans l’item « Des millions de personnes ont été assassinées. L’holocauste et le génocide le plus meurtrier de l’histoire« , seule la première phrase est surlignée en vert ?
Et pour ChatGPT.

On le voit sur ce sujet comme sur tant d’autres, les progrès sont manifestes et significatifs, grâce (notamment) au travail sur ce que l’on nomme « fine-tuning » c’est à dire un affinage des données et des réponses selon des contraintes spécifiques (ici par exemple nettoyer et toiletter le champ des possibles pour ne pas risquer l’accusation d’antisémitisme ou de révisionnisme).
Les principaux acteurs du secteur de l’IA et des artefacts génératifs (Google – Gemini, OpenAI – ChatGPT mais il faudrait aussi bien sûr parler de Meta – LLama, Mistral – Mistral et quelques autres dont Perplexity, Albert, etc.) se livrent aujourd’hui à une guerre qui n’est pas sans rappeler celle des grands moteurs de recherche du début des années 2000. OpenAI a d’ailleurs récemment lancé un produit spécifique, SearchGPT, qui dit tout de ses ambitions sur le marché de la recherche d’informations identifié comme un levier de croissance majeur (même si, magie du marketing, l’actuel ChatGPT est de fait déjà utilisé comme un moteur de recherche). De cette guerre autour de l’intégration du Search dans les artefacts génératifs (et réciproquement) il sortira d’ailleurs probablement la même chose que de la guerre des moteurs de recherche des années 2000 à savoir :
- un ou deux acteurs se partageront l’essentiel du marché et les autres grignoteront les restes
- il est plus que probable que ces 1 ou 2 (ou 3) acteurs se trouvent parmi les premiers arrivés sur le marché (dont OpenAI et Google)
- les technologies seront grosso modo équivalentes en termes de résultats (avec des variations dans la pertinence des résultats liés à des secteurs ou à des types de requête)
- c’est l’usage et l’antériorité (et aussi quand même un peu le marketing et la R&D) qui leur permettront de se maintenir en situation de quasi-monopole, probablement au moins la prochaine décennie.
Des progrès manifestes donc, la nécessité de « cadrer » et « fine-tuner » tout ce qui peut l’être au risque de produire des aberrations comme le fait actuellement Grok (l’IA d’Elon Musk). Mais plusieurs problèmes évoqués dans cet article (autour des heuristiques de preuve notamment) qui s’ajoutent au fait que jamais les conditions de production de ces « réponses » ne pourront s’aligner entièrement sur les conditions de production et de stabilisation des savoirs et des connaissances, en tout cas pas tant que ces acteurs de la recherche ou des médias sociaux ou de l’IA obéiront structurellement à des logiques marchandes qui sont celles des entreprises privées à la lutte pour le contrôle d’un marché et de nos attentions.
Holocauste vient étymologiquement du grec « Holos » (entier) et « Kautos » (brûler). Hologramme vient du grec « Gramma » qui veut dire « lettre, écriture ».
Cet exemple de l’Holocauste et de ce qu’il en advient quand on interroge moteurs de recherche (« l’Holocauste a-t-il vraiment existé ?« ) et artefacts génératifs, pose littéralement la question de « l’holo – gramme », c’est à dire la question de ce qu’il est possible, pour un artefact génératif, « d’écrire en entier ». Et « écrire en entier » est ici à prendre dans deux sens différents. Le premier considère cette entièreté comme une complétude sincère, c’est à dire ce que l’on acte comme vérité (vérité historique en l’occurence) ; le second voit dans cette entièreté celle de tous les possibles et les probables, y compris donc le fait qu’il n’aurait pas existé dans le délire révisionniste ou négationniste. Le cadre interprétatif (herméneutique) qui sera donc donné à ces réponses sera déterminant pour notre capacité collective de s’informer et de faire mémoire à l’échelle des outils et usages numériques.
So what ?
Ces connaissances et informations digérées par des acteurs technologiques, ces agencements, ces matrices, ces architectures – essentiellement – invisibles, furent pendant les 25 dernières années celles d’une liste de résultats sur laquelle il nous fallait nécessairement proposer un cadre interprétatif et hors laquelle cette liste n’avait aucune valeur. C’est moi, qui à partir d’une liste de résultats, vais produire une première synthèse, fabriquer un premier cadre de compréhension et d’interprétation, choisir de m’en tenir là où d’activer ensuite tout ou partie de ces liens qui me sont proposés.
Avec l’arrivée des artefacts génératifs dans le monde du Search, quand je consulte non plus une liste de résultats mais un discours sur ces résultats, j’ai déjà un premier cadre interprétatif, une première heuristique qui est posée et dans laquelle je vais m’inscrire en continuité soit pour l’accepter soit … soit pour en générer une autre dans laquelle je vais m’inscrire en continuité soit pour l’accepter soit … ad libitum.
Avec les artefacts génératifs, l’interface homme machine se trouve transformée. Je n’interagis plus avec des éléments composables, détachables (Simondon écrivait « qu’un objet technologique est produit lorsqu’il est détachable ») parmi lesquels c’est à moi que revient la tâche de construire un itinéraire cognitif et interprétatif, j’interagis avec une matrice discursive déjà établie, disposant de ses propres règles herméneutiques plus ou moins explicites et activables (le surlignage dans Gemini par exemple) et au regard de laquelle il m’est d’autant plus difficile de produire un contre-discours ou d’en discuter le fondement que le cadre énonciatif initial postule que je ne dispose pas des connaissances me permettant de le faire (puisque ma requête est l’aveu même de cette – relative – ignorance).
Pour le dire autrement (et peut-être plus simplement) les pages de résultat de recherche sont des matrices discursives qui donnent à lire, à voir et à naviguer dans une polyphonie, dans plusieurs voix. Les résultats de recherche formulés par les IA et autres artefacts génératifs sont monophoniques. Ils ne parlent que d’une seule voix et font souvent silence du reste.
Face à une liste de résultats, si l’on tente d’en schématiser les ressorts d’interaction, cette interaction est forte puisqu’elle nécessite à la fois une activité de navigation, de choix, et d’activation (visiter certains liens ou pas). Face à un discours de réponse d’un artefact génératif, l’interaction est faible puisqu’elle n’augure que d’une fin, ne propose pas – ou en dernière intention – d’activité de navigation, de choix, ou d’activation hors celle d’une réitération. C’est la poursuite de la stratégie de ces entreprises qui visent à nous garder captifs et captives de leur environnement et c’est également le cas depuis longtemps du moteur de recherche Google qui s’est toujours voulu un moteur de réponses, avec vocation de nous afficher directement lesdites réponses dans sa landing page plutôt que de prendre le risque de nous envoyer naviguer loin de lui. A ce titre on peut affirmer que Gemini est l’aboutissement de la stratégie poursuivie par le moteur dans ce cadre. Mais.
Mais une liste de résultats dans un moteur de recherche est un « discours de score », c’est à dire que ce qui est donné à voir c’est la verticalisation du score de pertinence / popularité calculé par l’algorithme : en haut le plus pertinent / populaire, en bas le moins pertinent / populaire.
Alors qu’un ou plusieurs paragraphes résumant une liste de résultats de recherche, comme le proposent ces artefacts génératifs, c’est tout autre chose. C’est une forme de « discours d’escorte » comme le définissait Gérard Genette c’est à dire un paratexte qui accompagne un écrit pour indiquer les interprétations de lecture de celui-ci. A la différence que ce discours d’escorte avance en partie masqué. Il ne dit jamais entièrement ce qu’il est ni ce qu’il prétend interpréter. Et que nous ne le reconnaissons pas comme tel.
Aucune de ces deux formules n’est neutre ou entièrement satisfaisante. Le discours de score est nécessairement biaisé et le choix même de ces scores peut survisibiliser ou invisibiliser des éléments pourtant essentiels à la compréhension fine de la requête. Et le discours d’escorte, en produisant à notre place un cadre interprétatif lui-même toujours dépendant d’un discours de score désormais totalement invisible, nous dépossède de capacités fines d’intellection et de compréhension.
Vous me direz – et vous aurez raison puisque je l’ai moi même écrit et théorisé – que de la même manière les « simples » listes de résultats des moteurs de recherche sont déjà des formes d’éditorialisation, ne serait-ce que par le choix qui est fait de classer ou de ne pas classer tel ou tel contenu (choix qui est fait algorithmiquement mais les algorithmes ne sont que la décision de quelqu’un d’autre). Certes. Mais l’une des différences majeures réside dans la capacité d’authentifier les sources primaires sur lesquelles sont construites ces éditorialisations. Dans le cas des pages de résultats des moteurs de recherche, ces sources primaires sont les pages web elles-mêmes (les pages web, ou les vidéos, ou les articles de journaux, etc …). Dans le cas des artefacts génératifs, ces sources primaires sont aveugles pour celui ou celle qui établit la requête et en consulte le résultat.
Itération et délibération. Génération et dégénérescence.
Pour conclure (il est temps ;-), il est à mon avis deux grandes question fondamentales aujourd’hui autour de ces LLM et artefacts génératifs dans le cadre de leur utilisation à des fins d’information ou de recherche d’informations.
La première question fondamentale, et qui l’est aujourd’hui avec ces artefacts génératifs comme elle l’était hier avec les landing pages des moteurs de recherche ou les fils personnalisés des médias sociaux, c’est la question de la part de la délibération dans l’itération. A chaque itération c’est à dire à chaque répétition, à chaque nouvel affichage, à chaque nouvelle formulation, quelle est la part de la délibération et quelle est la transparence de cette délibération pour qu’elle puisse collectivement nous garantir d’être davantage une forme de libération qu’une forme d’aliénation ? Qu’est-ce qui, dans les informations générées et proposées, a fait l’objet d’un délibéré, d’une délibération, dans quel cadre, avec quelles données et quelle(s) garantie(s) (éthique, juridique, véridictionnelle, etc.) ?
La réponse à cette question n’augure rien de satisfaisant pour l’avenir puisque nombre de recherches pointent et démontrent l’opacité des jeux de données qui alimentent les technologies de ces artefacts génératifs, l’immensité presqu’insondable sur laquelle ils reposent et « s’entraînent », ces Big Data devenues Too Big et ces troublants perroquets stochastiques dont nous sommes incapables d’adresser la voix, la phrase et la logique qu’ils répètent et répètent encore.
La seconde question fondamentale est celle de l’équilibre entre ces générateurs et l’ensemble documentable des générations produites (qu’elles soient textuelles, icôniques ou audiovisuelles) et la dégénérescence produite par l’utilisation de ces générations comme éléments de corpus pour les suivantes. Cette question que j’avais déjà soulevée dans d’anciens articles sur le sujet et dans cet excellent ouvrage (hahaha), vient d’être remarquablement documentée dans un article de Shumailov, I., Shumaylov, Z., Zhao, Y. et al. publié dans Nature 631, 755–759 (2024) et titré : « AI models collapse when trained on recursively generated data » (Les modèles d’intelligence artificielle s’effondrent quand ils sont entraînés de manière récursive sur des données générées).
En voici les résultats :
« The development of LLMs is very involved and requires large quantities of training data. Yet, although current LLMs, including GPT-3, were trained on predominantly human-generated text, this may change. If the training data of most future models are also scraped from the web, then they will inevitably train on data produced by their predecessors. In this paper, we investigate what happens when text produced by, for example, a version of GPT forms most of the training dataset of following models. What happens to GPT generations GPT-{n} as n increases? We discover that indiscriminately learning from data produced by other models causes ‘model collapse’—a degenerative process whereby, over time, models forget the true underlying data distribution, even in the absence of a shift in the distribution over time. »
Ce qui donne (traduit via DeepL) :
« Le développement des LLM est très complexe et nécessite de grandes quantités de données d’entraînement. Cependant, bien que les LLM actuels, y compris GPT-3, aient été formés sur des textes essentiellement générés par des humains, cette situation pourrait changer. Si les données d’entraînement de la plupart des futurs modèles sont également extraites du web, ils s’entraîneront inévitablement sur des données produites par leurs prédécesseurs. Dans cet article, nous étudions ce qui se passe lorsque le texte produit, par exemple, par une version de GPT constitue la majeure partie de l’ensemble de données d’entraînement des modèles suivants. Qu’advient-il des générations GPT GPT-{n} lorsque n augmente ? Nous découvrons que l’apprentissage sans discernement à partir de données produites par d’autres modèles entraîne un « effondrement du modèle » – un processus dégénératif par lequel, au fil du temps, les modèles oublient la véritable distribution sous-jacente des données, même en l’absence d’un changement dans la distribution au fil du temps. »
Je m’interroge depuis longtemps (et je ne suis pas le seul) sur le devenir de toutes ces générations possibles qui nous renvoie à l’imaginaire de Borges dans sa nouvelle « La bibliothèque de Babel« . Si l’ensemble des générations produites ont vocation (c’est bien le cas) à devenir de nouveaux éléments de corpus pour les suivantes, que deviendront les générations de textes et de scénarios racistes, sexistes, révisionnistes, etc ? Quelles bases de données alimenteront-elles ? A quelles éditorialisations nouvelles donneront-elles lieu ? Avec quelle possibilité d’en tracer l’historique et le devenir ? On pose souvent la question de l’avenir de l’intelligence articielle, mais l’avenir de l’intelligence artificielle (et des artefacts génératifs) pose, et avant toute autre, la question de notre rapport au passé.
François Chollet, l’un des scientifiques leaders de l’intelligence artificielle et du Deep Learning chez Google, alertait déjà en Mars 2022 : « On est proche du moment où on aura entraîné les modèles sur toutes les données textes humainement disponibles, on n’aura plus rien pour les alimenter. » Plus rien … si ce n’est le produit d’anciennes générations de texte.
Et à cela s’ajoute, comme le démontraient Sadasivan, Vinu Sankar, et al. dans leur article « Can AI-Generated Text be Reliably Detected ?« (Mars 2023), que la diversité des textes produits par ces artefacts génératifs est en train de devenir presque aussi vaste que celle de ceux produits par l’être humain, rendant toute tentative de détection et de discernement essentiellement vaine à moyen terme.
Détecter l’utilisation abusive des modèles linguistiques dans le monde réel, comme le plagiat et la propagande de masse, nécessite l’identification du texte produit par toutes sortes de modèles linguistiques, y compris ceux sans filigrane. Cependant, à mesure que ces modèles s’améliorent avec le temps, le texte généré semble de plus en plus semblable au texte humain, ce qui complique le processus de détection. Plus précisément, le total
distance de variation entre les distributions des séquences de texte générées par l’IA et générées par l’homme diminue à mesure que les modèles de langage deviennent plus sophistiqués.
Personne n’est aujourd’hui en capacité de dresser l’avenir clair de la place qu’occuperont ces technologies d’IA, via leurs artefacts génératifs, dans nos futures pratiques informationnelles. Par contre l’état de la recherche est assez clair sur ces deux questions fondamentales : premièrement, la part traçable, documentable et réellement délibérative de ces itérations diminue constamment (lorsqu’elle n’est pas intentionnellement masquée) et pose en cela une question fondamentale en termes de confiance informationnelle ; et – en plus de tous les autres problèmes posés – la dégénérescence des productions discursives automatisées qui ont vocation à devenir source de nos routines informationnelles, cette dégénérescence est certaine à court et moyen terme et pose la question d’un pourrissement inquiétant de nos environnement médiatiques nativement numériques.
One More Thing.
Si cet article vous a plu, intéressé, rendu curieux ou curieuse, vous pouvez commander (chez mon éditeur ou chez votre libraire) ce formidable ouvrage sur le sujet, « Les IA à l’assaut du cyberespace : vers un web synthétique » dont je vous racontais ici la génèse 🙂
Bonjour
J’ai une question à propos de votre livre, est ce qu’il sera disponible en version électronique à un moment ?
Sinon merci pour votre article. Je ne tombe que trop rarement sur ce type de propos. C’est bien dommage. ( Article que j’ai trouvé via mastodon )
Bonjour (et merci 🙂 Non pour l’instant il n’y a pas de parution numérique de prévue.
Cordialement.