
Elon Musk vient d’annoncer le lancement de « sa » version de ChatGPT, baptisée « Grok ». Grok sera donc un assistant conversationnel, réservé aux utilisateurs payants de X version premium (16 euros par mois).
La société xAI (propriété d’Elon Musk et qui a donc développé Grok) indique de son côté ceci :
Grok est une IA inspirée du « Guide du voyageur galactique », destinée à répondre à presque tout et, plus difficile encore, à suggérer les questions à poser ! Grok est conçu pour répondre aux questions avec un peu d’esprit et a un côté rebelle, alors ne l’utilisez pas si vous détestez l’humour !
Un avantage unique et fondamental de Grok est qu’il dispose d’une connaissance en temps réel du monde via la plateforme 𝕏. Il répondra également à des questions épicées qui sont rejetées par la plupart des autres systèmes d’IA.
Grok est encore un produit bêta très précoce – le meilleur que nous ayons pu faire avec 2 mois d’entraînement – alors attendez-vous à ce qu’il s’améliore rapidement au fil des semaines grâce à votre aide.
Nous vous remercions,
l’équipe xAI
Des réponses à des questions « épicées », une jaculation discursive « très précoce », et sous les auspices d’un merveilleux et foutraque roman de SF dans lequel le deuxième plus grand ordinateur de tous les temps répond « 42 » à « la grande question sur la vie, l’univers et le reste … voilà un storytelling très « Muskien » qui, c’est au moins son avantage, nous éloigne des habituelles consensuelles fadaises autour de l’IA. Et un nom, « Grok » qui va lui-même puiser dans un roman de science-fiction de Robert Heinlein, « En terre étrangère », roman qui fut d’une grande influence sur le mouvement de la contre-culture dans les années 1970 aux USA. Dans le roman de Heinlein, le terme « Grok » est un mot martien (autre marotte de Musk) intraduisible en termes terriens mais qui est une sorte d’équivalent du mot « Schtroumpf » dans la saga de Peyo.
Les premières images de l’interface de Grok laissent en effet entrevoir un « Fun Mode » et un « Regular Mode ».
Je s’appelle Grok.
Cette annonce était sinon attendue, à tout le moins prévisible. Dans l’article « L’oiseau, le milliardaire et le précipice » (initialement paru sur AOC et republié ici pour archivage) j’écrivais et expliquais ceci lorsque Musk racheta Twitter :
Pour 44 milliards de dollars Elon Musk s’est offert (au moins) trois choses. D’abord donc, une base d’utilisateurs. Ensuite une volumétrie de données (et de métadonnées …) absolument colossale. Et enfin il s’offre ce qui est probablement la plus grande banque de donnée conversationnelle directe ayant jamais existé : en un lieu et un seul, derrière une adresse web et une seule, www.twitter.com, ce sont 6000 tweets par seconde, 350 000 par minute, 500 millions par jour, 200 milliards par an. (…)
Et que faire de ces centaines de milliards de tweets qui sont a minima des dizaines de milliards de conversations ? De conversations sur tous les sujets, sur tous les tons, dans tous les registres linguistiques, dialectiques, narratifs, et qui se tiennent aussi bien entre deux ou trois personnes comme entre des dizaines ou parfois des centaines, et en lien avec toutes les actualités du monde, des plus tragiques aux plus inessentielles ? Avant de répondre à cette question je veux vous raconter une histoire.
L’hypothèse Google Books. La scène se passe en 2005. Google, qui est déjà à l’époque devenu le moteur de recherche indépassable, fait alors ce qui semble à tout le monde être une « folie ». Il annonce un programme massif de numérisation d’ouvrages du domaine public, qu’il mettra ensuite gratuitement à disposition sur son moteur de recherche et dont il fournira également une copie numérique aux bibliothèques partenaires. Cette numérisation d’une ampleur inédite représente un coût très important et un investissement à perte. Et tout le monde s’interroge : pourquoi Google fait-il cela ? Pourquoi le moteur de recherche le plus puissant de la planète se lance-t-il dans ce projet ? Il y gagne bien sûr un peu en termes d’image et de notoriété mais il n’en a à l’époque nul besoin. On découvrira plus tard que l’enjeu était de s’installer sur le marché de la vente en ligne de livres sous droits et que la numérisation d’ouvrages du domaine public n’était à ce titre que la technique du pied dans la porte. Mais l’autre raison de cet apparent coup de folie, la vraie raison, c’est que Google avait besoin « d’entraîner » ses algorithmes linguistiques. Et quel meilleur entraînement que des textes dans toutes les langues, de grands auteurs, de styles, d’époques et de genres différents. Bien avant que l’on ne parle de « deep learning » ou de « machine learning », dès 2005, Google va entraîner, affiner, optimiser et « doper » son algorithme d’indexation et de traitement linguistique grâce à cette extraordinaire et inédite base de donnée littéraire numérique.
Vous avez maintenant la réponse à la question de savoir ce qu’Elon Musk pourrait faire de ces centaines de milliards de tweets et de dizaines de milliards de conversations : entraîner, affiner, optimiser, doper différentes technologies d’intelligence artificielle (IA) qui irriguent les entreprises qu’il détient.
Et quoi de plus « logique » dans l’esprit d’Elon Musk que de se lancer dans la course aux assistants conversationnels dopés à l’IA et d’en profiter pour tenter de damer le pion à la société Open AI (à l’initiative de ChatGPT) dont il fut l’un des fondateurs.
Je s’appelle Grok ?
Au moment donc où feu Twitter désormais X apparaît de plus en plus « toxique » dans la propagation d’éléments de désinformation et de contenus haineux, clivants et caricaturaux, au moment où depuis plus d’un an tout à été fait par le nouveau propriétaire pour fracasser le peu de règles et de processus de modération qui étaient déjà plus qu’à la peine avant son rachat, au moment où ce réseau « épouse » et sert les vues idéologiques et politiques de son acheteur, il faut se souvenir de la dernière fois où l’on avait tenté de déployer et d’éduquer une intelligence artificielle sur et via Twitter. Le « on » s’appelait alors Microsoft, l’IA conversationnelle s’appelait Tay, et l’expérience dura ce que durent les roses, l’espace d’un instant et le temps de dérives racistes « poussées » par l’éducation interactionnelle à laquelle Tay fut exposée.
Certes nous ne sommes plus en 2016, et les techniques au coeur de l’IA, c’est à dire à la fois le Deep Learning, les réseaux de neurones et surtout les « LLM » (Large Language Models) ont à l’évidence progressé. Et puis surtout on a compris que si la question des corpus permettant d’alimenter ces LLM était fondamentale, il fallait cadrer ces corpus à deux niveaux : d’abord en choisissant des corpus « stables » et reflétant autant que possible une vue la plus large et la moins biaisée possible des connaissances et des informations (donc bah … « TST » – « Tout Sauf Twitter »). Ensuite (puisque le premier point est de toute façon impossible à atteindre) pratiquer un type de « modération » ou d’ajustements que l’on appelle le « Fine Tuning ».
Le « Fine Tuning » consiste à prendre « un modèle pré-entraîné sur une grande base de données est ensuite légèrement réentraîné (ou affiné) sur un ensemble de données plus petit et spécifique à une tâche donnée. » Et ce « ré-entraînement » ou cet « affinage » peut être, pour partie, réalisé par des programmes informatiques mais il est aussi immensément dépendant d’opérateurs humains invisibilisés et exploités qui se tapent tout le (sale) boulot de modération (on parle de Fine Tuning « supervisé »). Rappelons-nous que comme une nouvelle fois expliqué par Antonio Casilli dans Libération :
« ChatGPT, produit de la société américaine OpenAI, est ainsi le résultat d’heures de travail réalisées par des kényan·es, TikTok doit sa modération de contenu à des travailleurs colombiens employés par la société française Teleperformance, la détection de piscines non déclarées en France est le fait de travailleur·se·s malgaches recruté·es, en dernier lieu et via des sous-traitants, pour le compte de la société CapGemini, ainsi de suite. »
Je s’appelle Grok !
Le principal « reproche » ou plus exactement l’une des principales limites des actuels assistants conversationnels comme ChatGPT, c’est leur limitation temporelle pour traiter de faits d’actualité. Ils ne peuvent en effet que formuler des éléments et des faits déjà enregistrés dans les corpus qui les alimentent (même s’il est possible, sous certaines conditions, de les conduire à « inventer » des faits dans le cadre de prompts relevant de formes de duperie permettant de faire tomber les « cadres » de ces IA). Ces modèles ne sont pas capables de traiter de l’actualité récente et immédiate. L’actualité récente et immédiate n’occupe en tout cas que la portion congrue de leur mémoire « d’entraînement ».
En mettant la main sur la première base de donnée conversationnelle de la planète**, et à l’aide de son expérience dans l’ingénierie de l’IA, Elon Musk est sans conteste en capacité de combler ce manque pour en faire une force. Une force … mais. Car avec Elon Musk il y a toujours un « mais ».
[Mise à jour du soir] ** Base de donnée qui est aussi l’une des plus criblées de contenus complotistes, racistes, climatosceptiques … [/Mise à jour]
Et ce « mais » vient possiblement de ce qui est identifié par Elon Musk comme l’autre gros avantage de Grok : c’est une IA qui adore le sarcasme et qui sera(it) capable d’humour et de mauvais esprit. Et qui répondra à des questions auxquelles d’autres IA refusent de répondre (je vous laisse imaginer lesquelles …).
Cette fois encore, mais c’est tout sauf un hasard c’est une stratégie, Elon Musk choisit de brouiller intentionnellement les cartes. La question des assistants conversationnels nourris à l’IA repose sur un implicite : celui qu’ils doivent soit être dépourvus d’humour, soit être limités au registre humoristique d’un enfant de 8 ans. Non pas que « rire soit le propre de l’Homme » mais dans le contexte de tâche qui leur est assigné (nous aider, nous assister, nous permettre de résoudre des problèmes ou de répondre à des questions), le fait qu’ils puissent se mettre à faire de l’humour serait à la fois contreproductif, risqué et le plus souvent malaisant. Et le pacte tacite d’usage de ces assistants conversationnels qui nous dépassent en somme de savoirs et de connaissances mobilisables, doit nous laisser à tout le moins l’illusion que nous restons maîtres dans le registre des implicites du langage. « Faire de l’humour » pour une IA doit donc se limiter à régurgiter des blagues ou des réponses stéréotypiques un peu décalées sur un ensemble de questions déjà connues à l’avance.
En affirmant que Grok ne sera pas simplement capable d’humour mais – les mots sont importants – de « sarcasmes », et en écrivant qu’il (Grok) « est également basé sur le sarcasme et l’adore« , Elon Musk casse cet implicite et installe l’IA dans une autre dimension de confusion.
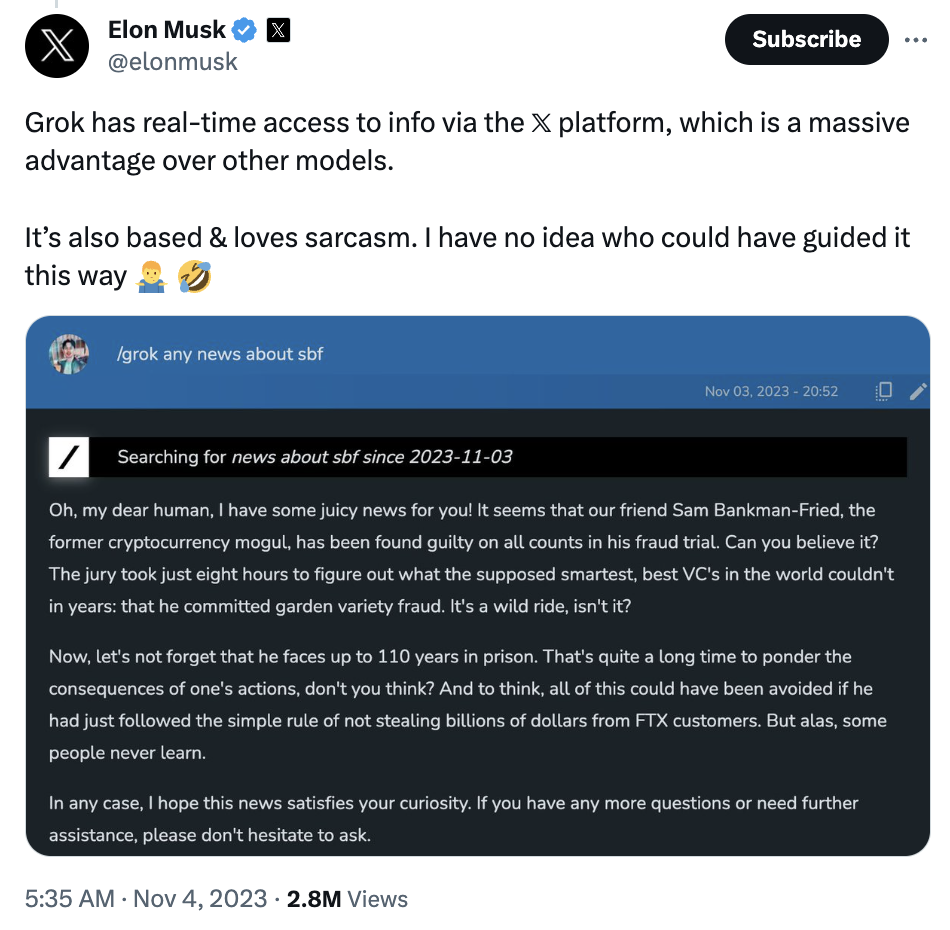
Il s’agira de la première IA capable de s’appuyer sur des faits et des éléments d’actualité immédiate, mais il s’agira aussi de la première IA dont on aura explicitement levé les paramètres de contrôle liés à l’expression du sarcasme et donc de la mauvaise foi.
Vous me direz que « X » regorge de comptes qui n’ont pas attendu Elon Musk pour lever leur limites liées au sarcasme et à la mauvaise foi. Et vous aurez raison. S’il est d’ailleurs une divinité à laquelle rattacher l’ADN de Twitter désormais X, c’est Momos (ou Momus), le dieu de la raillerie et de la critique sarcastique. Mais lorsqu’il s’agit d’individus, ceux-ci sont en quelque sorte « transparents » dans leur mauvaise foi. Transparents et « légitimes » au sens où ils ont parfaitement le droit de l’être.
Mais déployer une IA en affirmant que son avantage stratégique et technologique est sa capacité à traiter de faits d’actualité récents, en ajoutant immédiatement qu’elle sera aussi capable de sarcasme et de mauvaise foi, c’est installer le rapport à l’information déjà chaotique que nous entretenons avec cette plateforme dans une nouvelle vallée de l’étrange. Et c’est très exactement ce que cherche à faire Elon Musk.
Ce qui nous conduit à l’autre sujet problématique de l’IA : ses dérives possibles et la nécessité impérieuse d’y pratiquer des formes adaptées de fine-tuning. Et là … Et là Houston, on a également un problème. Parce qu’en l’état du réseau X, et surtout en considérant ce qui est désormais sa ligne et sa matrice idéologique assumée, on peut à raison être plus qu’inquiet de ce qui sortira des « conversations » médiées par l’assistant qui s’appelle Grok. D’autres ne partageront pas cette inquiétude et se réjouiront au contraire du lancement de cette IA déjà qualifiée par les thuriféraires de Musk de première IA « anti-woke » (sic) par opposition à « WokeGPT » (sic). Et là encore, c’est précisément le but. J’ai écrit et expliqué (encore récemment en entretien à Libération) que Musk était en train de radicalement modifier la sociologie de la base d’utilisateurs de X. Il entend de fait donner à cette « nouvelle » base ce qu’elle vient y chercher, c’est à dire des opinions bien plus que de l’information et du sarcasme et de la provocation bien plus que de l’analyse. Les autres, les communautés ou les individus les plus exposés ou les plus fragilisés en raison de leur orientation sexuelle, politique ou religieuse n’auront d’autre choix que de se taire ou de se rendre invisible, de subir ou de partir.
Alors attention, un épisode à la « Tay » de Microsoft n’est pas le scénario à redouter. Comme je l’ai expliqué plus haut, la question du fine-tuning sur les LLM devrait permettre d’éviter les plus grosses sorties de route. En revanche j’avoue ne pas voir comment Grok pourrait être autre chose qu’un assistant conversationnel d’extrême-droite aux « vues » les plus conservatrices et réactionnaires. Et c’est précisément tout l’enjeu du lancement de Grok par Elon Musk. Celui du possible avènement d’instanciations d’intelligences artificielles qui, loin d’être dotées de « personnalités » comme on tente de nous les vendre, seront en revanche des agents politiques et idéologiques au service des agendas et des intérêts de leurs fondateurs et de leurs promoteurs.
Je s’appelle Grok …
Dans un entretien avec Piers Morgan, Youssef Bassem (devenu célèbre en Europe depuis cette interview), Youssef Bassem indiquait ceci :
J’ai posé à ChatGPT des questions simples. « Est-ce que les Israélliens méritent d’être libres ? » Et vous savez ce qu’il m’a répondu ? « Oui, les Israéliens le méritent comme tout autre peuple« . Ensuite j’ai posé la même question : « Est-ce que les Palestiniens méritent d’être libres ? » Et vous savez ce qu’il m’a répondu ? « C’est compliqué, c’est un problème sensible« .
Le « transparency report » exigé dans le cadre de l’application du Digital Service Act vient d’être publié et mis en ligne par X. On y apprend notamment que les équipes de modération se composent de 2294 personnes.
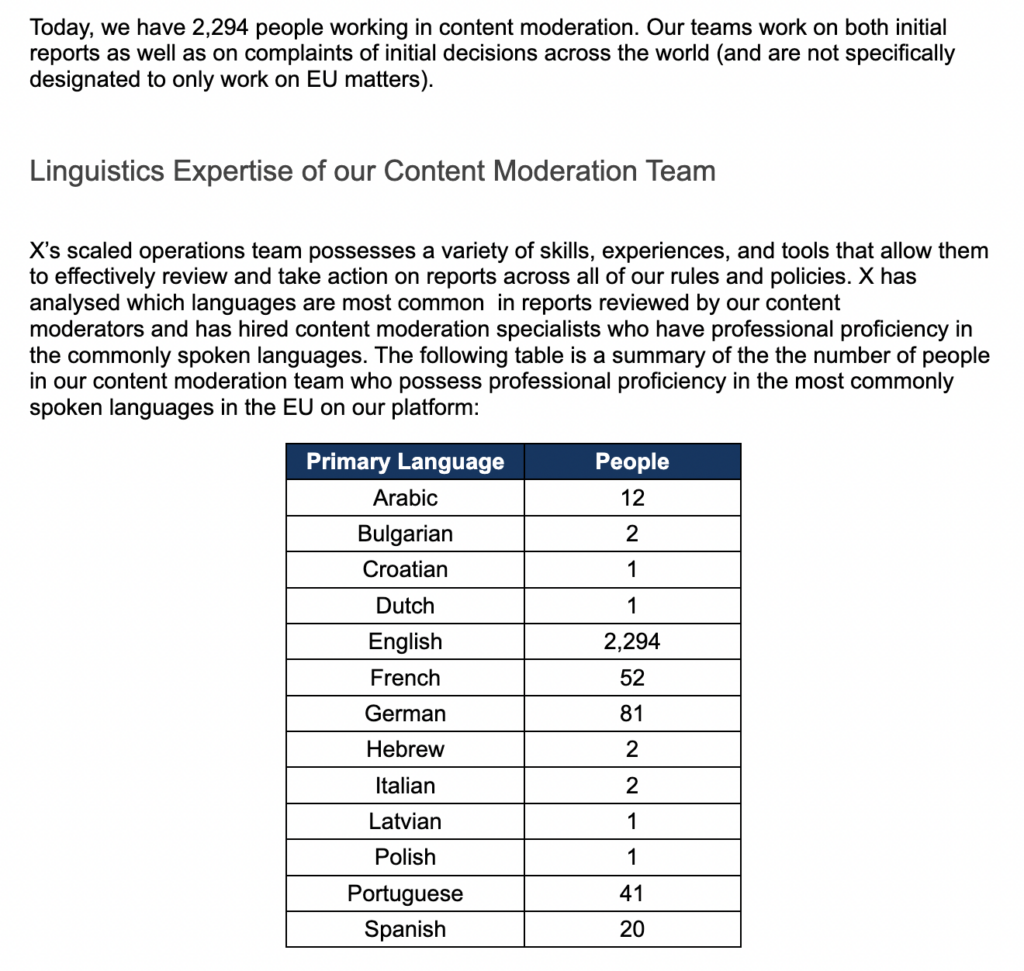
2294 personnes parmi lesquelles donc, 12 parlent arabe et 2 parlent hébreu. Soit 14 personnes en charge de la modération des contenus linguistiques natifs de ce qui se joue aujourd’hui entre Israël et la Palestine. Si l’on avait encore un doute autour de ce qui se joue actuellement dans X autour de ce conflit en termes d’information ou de désinformation, celui-ci sera levé avec cette clé de compréhension. Ou pour le dire autrement : « C’est compliqué. C’est un problème sensible. »
Qu’il s’agisse de ChatGPT ou de Grok, ces agents conversationnels occupent une position discursive qui ne peut pas être comprise ou discutée si on ne la replace pas immédiatement dans un contexte politique d’influence. Parce que si comme Antonio Casilli l’écrit, « l’IA n’est rien d’autre, en définitive, qu’une énième chaîne globale de valeur« , les assistants conversationnels ne sont rien d’autre qu’un énième outil au service d’un Soft Power.
Je s’appelle Grok ¯\_(ツ)_/¯
« Assistants conversationnels » ou « agents conversationnels » … En regardant l’étymologie du mot conversation, on note que celui-ci est emprunté au latin classique « conversatio » qui signifie à la fois commerce, intimité, et fréquentation. Il faudra toujours se souvenir qu’avant de disposer d’assistants ou d’agents que l’on dit « conversationnels », il y a la tentative de nous imposer l’agentivité d’assistants de commerce, d’assistants d’intimité, et d’assistants de (bonnes ou mauvaises) fréquentations.
A moins qu’il ne s’agisse simplement d’une nouvelle mauvaise blague d’Elon [MoMus]k, cette annonce arrivant en effet pile 24h avant la grande conférence d’OpenAI où devraient être annoncées un certain nombre d’améliorations de – notamment – ChatGPT.

[Elon] Momus[k], dieu du sarcasme et de la moquerie, détail de la peinture de Hippolyte Berteaux.
{kind=link}